Analysing molecular dynamics simulations¶
Author: Giacomo Meanti
In this tutorial we will do a simple spectral analysis of a molecular dynamics simulation of the alanine dipeptide. This small molecule is often used as a test bench for algorithms working on MD since it provides interesting, slow dynamics while being small and easy to work with.
We will start by training a Nystroem reduced rank regression model with the NystroemKernelRidge class and a Gaussian kernel, and from there move to the spectral analysis of eigenvalues and eigenfunctions of the estimated Koopman operator.
Using the Nystroem approximation allows us to run a full analysis of MD data in a few seconds, without needing to subsample the trajectories too much (we will be training models on 25k and 50k points in a matter of seconds).
Setup¶
[1]:
import os
from urllib.request import urlretrieve
import matplotlib.pyplot as plt
import numpy as np
from matplotlib import colors
from kooplearn.kernel import NystroemKernelRidge
Download the data¶
The data consists of 3 250ns long independent molecular dynamic runs of the alanine dipeptide. The first file contains the backbone dihedral angles \(\phi, \psi\). They are known to provide enough information to identify the slow transitions of the dipeptide.
We will not use the dihedrals for training but only for the subsequent analysis: we will show that a model trained on the heavy atom pairwise distances (contained in the second file we’re downloading) can recover the same slow transitions as can be done by analyzing the dihedrals.
In a more realistic example, one would not have access to the dihedrals but would still be interested in recovering slow transitions of the molecule.
For more information about the data, see https://markovmodel.github.io/mdshare/ALA2/#alanine-dipeptide
[2]:
base_url = "http://ftp.imp.fu-berlin.de/pub/cmb-data/"
files = [
"alanine-dipeptide-3x250ns-backbone-dihedrals.npz",
"alanine-dipeptide-3x250ns-heavy-atom-distances.npz",
]
for file in files:
if not os.path.isfile(file):
urlretrieve(base_url + file, file)
We will use the first of three simulations for training and the second for testing. Here we plot (part of) the test dataset, both distances and dihedrals. Notice how the dihedrals show a sort of switching behavior. This becomes more clear in the Ramachandran plot (plotting each configuration’s \(\phi\) vs. \(\psi\) angle) where each cluster defines a specific state in which the protein can be in.
[3]:
train_distances = np.load(files[1])["arr_0"].astype(np.float64)
train_dihedrals = np.load(files[0])["arr_0"].astype(np.float64)
test_distances = np.load(files[1])["arr_1"].astype(np.float64)
test_dihedrals = np.load(files[0])["arr_1"].astype(np.float64)
time_ns = np.arange(train_distances.shape[0], dtype=np.float64)*1e-3
dt_ns = time_ns[1] - time_ns[0]
lagtime = 50
[ ]:
subsample = 20
x_ticks = np.arange(len(test_distances[::subsample]))[::2000]
x_tickslabels = [f"{x:.0f}" for x in (time_ns[::subsample])[::2000]]
fig, ax = plt.subplots(figsize=(4, 4))
ax.scatter(
test_dihedrals[::subsample, 0], test_dihedrals[::subsample, 1], s=2, color='k', alpha=0.2
)
ax.set_xlabel(r"Dihedral $\phi$")
ax.set_ylabel(r"Dihedral $\psi$")
ax.set_xticks([-np.pi, 0, np.pi], [r"$-\pi$", "$0$", r"$\pi$"])
ax.set_yticks([-np.pi, 0, np.pi], [r"$-\pi$", "$0$", r"$\pi$"])
ax.set_xlim(-np.pi, np.pi)
ax.set_ylim(-np.pi, np.pi)
ax.set_title("Ramachandran plot")
ax.margins(0)
ax.set_aspect('equal')
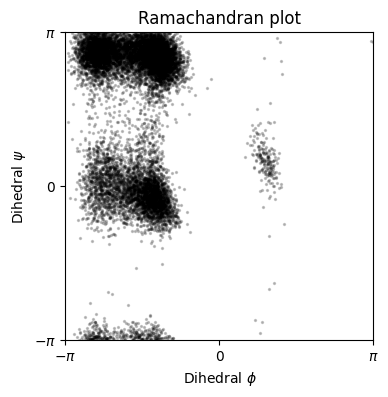
Model training¶
[5]:
print(f"Training data size: {train_distances.shape}")
print(f"Training a lagtime {lagtime}, corresponding to {dt_ns*lagtime} ns)")
Training data size: (250000, 45)
Training a lagtime 50, corresponding to 0.05 ns)
Build the Nyström reduced rank regression (N-RRR) model used for training. Important hyperparameters are:
The kernel, here a Gaussian (RBF) kernel.
The regularizer
alpha, should be a small positive number to ensure a stable solutionThe rank of the model to be trained: this depends on the system being analyzed.
The number of Nyström centers. Increasing this parameter makes the model slower to train but also more accurate.
Then we fit the estimator and make predictions on the test set.
[6]:
model = NystroemKernelRidge(
n_components=4, # Rank of the estimator
reduced_rank=True,
kernel="rbf",
alpha=1e-7,
gamma=2.0,
eigen_solver="arpack",
n_centers=600,
random_state=0,
lag_time=lagtime
)
[7]:
# Fit the Nystroem model
model.fit(train_distances)
# Predict on the test set and compute an error metric
X_test = test_distances[:-lagtime]
Y_test = test_distances[lagtime:]
Y_pred = model.predict(X_test) # Here we must pass the `X` part of the context
rmse_onestep = np.sqrt(np.mean((Y_pred - Y_test)**2))
print(f"Trained Nystroem RRR model with {model.n_centers} centers. "
f"Test RMSE on 1-step predictions = {rmse_onestep:.3f}")
Trained Nystroem RRR model with 600 centers. Test RMSE on 1-step predictions = 0.029
Spectral Analysis¶
Given the Koopman operator we’ve learned with Nystroem RRR we can analyze the dynamical system.
To do this we will use the spectrum of the operator: the eigenvalues and eigenvectors.
Each eigenpair describes a different component of the dynamics. Eigenvalues provide information about the relaxation time-scales of each component, larger eigenvalues correspond to slower processes, while smaller ones correspond to faster processes. On the other hand eigenvectors describe how each component varies in space. A common way to use the eigenvectors is to provide a dimensionality reduction of the original (high-dimensional) states onto the slowest dynamics corresponding to the eigenvectors with highest eigenvalues.
A special mention to the highest eigenpair which should have eigenvalue close to 1. This is the stationary dynamics, and is generally not used for spectral analysis.
First we use the model object to compute the eigenvalues of the operator, and the eigenvectors. Note that since the Koopman operator is technically an infinite dimensional operator it doesn’t have eigenvectors but eigenfunctions. For this reason, in order to have a concrete, finite-dimensional representation, the eigenfunctions must be evaluated on some data-points. Here we evaluate the right eigenfunctions on the subsampled test distances. Here it doesn’t really matter if you’re using
the X or Y part of the data.
Another thing to note is that the eigenvalues are returned in ascending order. We reverse the order to simplify the analysis later (since we’re most interested in the highest eigenvalues!)
[8]:
evals, evec_right = model.eig(eval_right_on=test_distances)
#Sort in descending order
evals = np.flip(evals)
evec_right = np.flip(evec_right, axis = 1)
Now we compute the time-scales implied by the eigenvalues. We have to take into account the fact that we’ve subsampled the data, and that we have generated trajectories such that the Koopman operator predicts Y from X where the pairs are time_lag time-steps apart. Knowing that the trajectories have a time-step of 1ps, we can compute the implied time-scales!
Note that:
we exclude the top eigenvalue (which corresponds to the stationary distribution), since it theoretically has an infinite relaxation time-scale
the spectrum for this system decays very rapidly as there are only two or three slow components to the dynamics. Since the other components are much faster, their true eigenvalues are very close to 0. The learned estimator will have some small errors due to having access to a finite dataset, so these eigenvalues might be estimated to be slightly lower than zero which causes them to have an undefined time-scale.
[9]:
tscales = -1 / np.log(evals.real.clip(1e-8, 1))
tscales_real = tscales * dt_ns * subsample
print(f"Stationary distribution eigenvalue: {evals[0].real:.3f}")
print(f"Other eigenvalues: {evals[1:].real}")
print(f"Implied time-scales: {tscales_real[1:]*1e-3} ns")
Stationary distribution eigenvalue: 1.000
Other eigenvalues: [0.93184568 0.50580947 0.00665998]
Implied time-scales: [2.83334047e-04 2.93429287e-05 3.99071054e-06] ns
Finally, we’re going to plot the first three eigenfunctions (excluding the stationary distribution) on the test data. We will superimpose the eigenfunctions, which in the plot below are represented with as the color, to the Ramachandran plot. Since we know that the Ramachandran plot provides a good clustering of the dynamics of the alanine dipeptide, we wish to see whether the color (eigenfunctions) also matches the clusters well.
By matching each eigenfunction to an eigenvalue we will also learn which transition between different areas of the Ramachandran plot is slowest.
[10]:
fig, axes = plt.subplots(ncols=3, figsize=(12, 5))
cmap = plt.cm.coolwarm
alpha = 0.5
s = 5
efun_vals = evec_right.real
# It might be useful to play with the mid value and range of the
# color-maps for each eigenfunction to get nicer visualizations.
vcenters = [0, 0 ,0]
halfranges = efun_vals.std(axis=0)[1:]
for i in range(len(axes)):
axes[i].scatter(
test_dihedrals[::subsample, 0], test_dihedrals[::subsample, 1],
c=efun_vals[::subsample, i + 1], s=s, cmap=cmap, alpha=alpha,
norm=colors.CenteredNorm(vcenter=vcenters[i], halfrange=halfranges[i])
)
axes[i].set_title(f"Implied timescale = {1000*tscales_real[i + 1].real:.1f}ps")
axes[i].set_xticks([-np.pi, 0, np.pi], [r"$-\pi$", "$0$", r"$\pi$"])
axes[i].set_xlabel(r"$\phi$")
axes[i].set_yticks([-np.pi, 0, np.pi])
axes[i].set_ylim([-np.pi, np.pi])
axes[i].set_xlim([-np.pi, np.pi])
if i == 0:
axes[i].set_yticklabels([r"$-\pi$", "$0$", r"$\pi$"])
axes[i].set_ylabel(r"$\psi$")
else:
axes[i].set_yticklabels([])
axes[i].set_aspect('equal')
axes[i].margins(0)
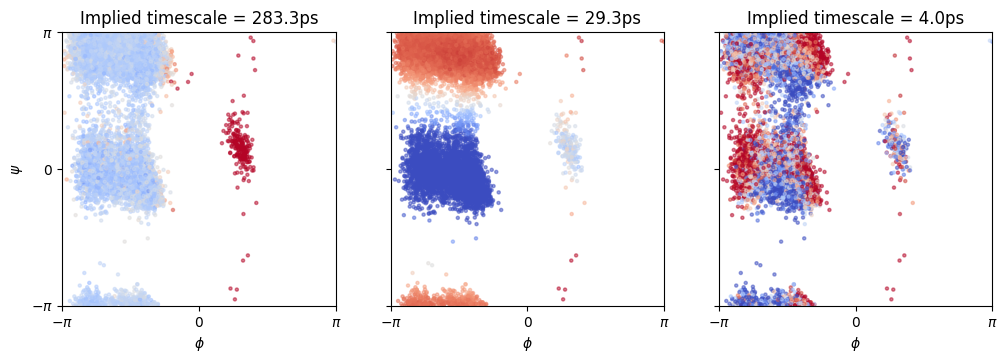
A brief comment on the eigenfunction plot:
the first panel shows that the slowest transition is between the right and left parts of the Ramachandran plot (high to low \(\phi\)).
the second panel shows that the second slowest transition is between \(\psi\approx 0\) and \(\psi\approx \pi\).
the third panel seems to be a very noisy component which cannot be reliably interpreted.
Consistency Analysis¶
An important aspect of a spectral analysis is that it should remain consistent across different time-lags.
We will analyze the implied time-scale (ITS) in terms of number of simulation steps (thus ignoring the real units of the simulation and the subsampling).
As we train models with increasing time lags (the time lag is the distance in number of simulation steps between x and y pairs), the estimated eigenvalues will become smaller since the model’s time-unit is the single time-lag, and relaxation becomes faster in terms of # of time-lags. However the ITS should remain relatively stable.
As we increase the time lags even further, faster dynamics will have relaxation times which are faster than a single time-lag, hence the model won’t be able to estimate those reliably.
We will see that the 1st ITS increases rapidly as we start increasing the time lags. This behavior is well documented in similar models. At some point however it converges, much before it becomes too fast to be resolved.
The 2nd ITS instead is much smaller, hence it won’t be resolved with higher time-lags. However we find that it converges very quickly at small time-lags.
We first define a helper function to train a model and return its ITS at a specific time-lag
[11]:
def train_model(lag_time: int, reduced_rank:bool):
train_set = train_distances
test_set = test_distances
model = NystroemKernelRidge(
n_components=4, # Rank of the estimator
reduced_rank=reduced_rank, # Using Principal Component Regression
kernel="rbf",
gamma=2.,
alpha=1e-7,
eigen_solver="arpack",
n_centers=300,
lag_time=lag_time,
random_state=0,
).fit(train_set)
X_test = test_set[:-1]
Y_test = test_set[1:]
Y_pred = model.predict(X_test) # Here we must pass the `X` part of the context
rmse_onestep = np.sqrt(np.mean((Y_pred - Y_test) ** 2))
evals = model.eig()
evals = np.flip(evals)[:4]
tscales = -1 / np.log(evals.real.clip(1e-8, 1))
tscales_real = tscales*lag_time
return rmse_onestep, tscales_real
Now we train one model per time-lag. Note that since the Nystroem method is very efficient we can quickly train many models even with many time-points.
[12]:
from collections import defaultdict
errors = defaultdict(list)
tscales = defaultdict(list)
lagtimes= np.linspace(1, 100, 10, dtype=int)
for method, reduced_rank in zip(['Reduced Rank', 'Principal Components (kDMD)'], [True, False]):
for lagtime in lagtimes:
error, tscale = train_model(lagtime, reduced_rank)
errors[method].append(error)
tscales[method].append(tscale)
Simple plot of the RMSE for different time-lags
[13]:
fig, ax = plt.subplots(ncols=3, figsize=(13.5, 3))
for method in errors.keys():
ax[0].plot(lagtimes, errors[method], '.-', label=method)
ax[0].set_xlabel("Lagtime")
ax[0].set_title("One-step RMSE")
ax[0].margins(x=0)
ax[0].legend(frameon=False)
for eig_id in [1, 2]:
ax[eig_id].fill_between([0, lagtimes[-1]], [0, 0], [0, lagtimes[-1]],color='k', alpha=0.2)
for method in errors.keys():
_tscale = [ t[eig_id] for t in tscales[method]]
ax[eig_id].plot(lagtimes, _tscale,'.-', label=method)
ax[eig_id].margins(0)
ax[eig_id].set_title(f"Implied Timescale {eig_id}\n(higher is better)")
